Gradient flows and the Łojasiewicz inequality, with an application to higher-order criticality
\newcommand{\abs}[1]{\left|{#1}\right|} \newcommand{\argmax}[1]{\underset{#1}{\operatorname{argmax}}} \newcommand{\argmin}[1]{\underset{#1}{\operatorname{argmin}}} \newcommand{\bareta}{{\overline{\eta}}} \newcommand{\barf}{{\overline{f}}} \newcommand{\barg}{{\overline{g}}} \newcommand{\barM}{\overline{\mathcal{M}}} \newcommand{\barnabla}{\overline{\nabla}} \newcommand{\barRcurv}{\bar{\mathcal{R}}} \newcommand{\barRmop}{\bar{R}_\mathrm{m}} \newcommand{\barRmoptensor}{\mathbf{{\bar{R}_\mathrm{m}}}} \newcommand{\barx}{{\overline{x}}} \newcommand{\barX}{{\overline{X}}} \newcommand{\barxi}{{\overline{\xi}}} \newcommand{\bary}{{\overline{y}}} \newcommand{\barY}{{\overline{Y}}} \newcommand{\bfeta}{{\bm{\eta}}} \newcommand{\bfF}{\mathbf{F}} \newcommand{\bfOmega}{\boldsymbol{\Omega}} \newcommand{\bfR}{\mathbf{R}} \newcommand{\bftheta}{{\bm{\theta}}} \newcommand{\bfX}{{\mathbf{X}}} \newcommand{\bfxi}{{\bm{\xi}}} \newcommand{\bfY}{{\mathbf{Y}}} \newcommand{\calA}{\mathcal{A}} \newcommand{\calB}{\mathcal{B}} \newcommand{\calP}{\mathcal{P}} \newcommand{\calC}{\mathcal{C}} \newcommand{\calE}{\mathcal{E}} \newcommand{\calF}{\mathcal{F}} \newcommand{\calG}{\mathcal{G}} \newcommand{\calH}{\mathcal{H}} \newcommand{\calJ}{\mathcal{J}} \newcommand{\calK}{\mathcal{K}} \newcommand{\calL}{\mathcal{L}} \newcommand{\ones}{\textbf{1}} \newcommand{\calM}{\mathcal{M}} \newcommand{\calN}{\mathcal{N}} \newcommand{\calO}{\mathcal{O}} \newcommand{\calS}{\mathcal{S}} \newcommand{\calT}{\mathcal{T}} \newcommand{\calU}{\mathcal{U}} \newcommand{\calV}{\mathcal{V}} \newcommand{\calW}{\mathcal{W}} \newcommand{\calX}{\mathcal{X}} \newcommand{\Cm}{{\mathbb{C}^m}} \newcommand{\CN}{{\mathbb{C}^{\,N}}} \newcommand{\Cn}{\mathbb{C}^n} \newcommand{\CNN}{{\mathbb{C}^{\ N\times N}}} \newcommand{\Cnn}{\mathbb{C}^{n\times n}} \newcommand{\CnotR}{{\mathbb{C}\ \backslash\mathbb{R}}} \newcommand{\col}{\operatorname{col}} \newcommand{\im}{\operatorname{im}} \newcommand{\complex}{{\mathbb{C}}} \newcommand{\Cov}{\mathbf{C}} \newcommand{\Covm}{C} \newcommand{\Ric}{\mathrm{Ric}} \newcommand{\Rmcurv}{\mathrm{Rm}} \newcommand{\D}{\mathrm{D}} \newcommand{\dblquote}[1]{``#1''} \newcommand{\dd}[1]{\frac{\mathrm{d}}{\mathrm{d}#1}} \newcommand{\ddiag}{\mathrm{ddiag}} \newcommand{\ddp}[2]{\frac{\partial #1}{\partial #2}} \newcommand{\Ddq}{\frac{\D}{\dq}} \newcommand{\dds}{\frac{\mathrm{d}}{\mathrm{d}s}} \newcommand{\Ddt}{\frac{\D}{\dt}} \newcommand{\ddt}{\frac{\mathrm{d}}{\mathrm{d}t}} \newcommand{\Ddttwo}{\frac{\D^2}{\dt^2}} \newcommand{\defeq}{\triangleq} \newcommand{\Dexp}{\D\!\exp} \newcommand{\error}{\mathrm{error}} \newcommand{\diag}{\mathrm{diag}} \newcommand{\Diag}{\mathrm{Diag}} \newcommand{\Vol}{\mathrm{Vol}} \newcommand{\polylog}{\mathrm{polylog}} \newcommand{\poly}{\mathrm{poly}} \newcommand{\dist}{\mathrm{dist}} \newcommand{\Dlog}{\D\!\log} \newcommand{\dmu}{\mathrm{d}\mu} \newcommand{\dphi}{\mathrm{d}\phi} \newcommand{\dq}{\mathrm{d}q} \newcommand{\ds}{\mathrm{d}s} \newcommand{\dt}{\mathrm{d}t} \newcommand{\dtau}{\mathrm{d}\tau} \newcommand{\dtheta}{\mathrm{d}\theta} \newcommand{\du}{\mathrm{d}u} \newcommand{\dx}{\mathrm{d}x} \newcommand{\Ebad}{E_\textrm{bad}} \newcommand{\Egood}{E_\textrm{good}} \newcommand{\eig}{{\mathrm{eig}}} \newcommand{\ellth}{$\ell$th } \newcommand{\embdist}{\mathrm{embdist}} \newcommand{\ER}{{Erd\H{o}s-R\'enyi }} \newcommand{\Exp}{\mathrm{Exp}} \newcommand{\expect}{\mathbb{E}} \newcommand{\expectt}[1]{\mathbb{E}\left\{{#1}\right\}} \newcommand{\expp}[1]{{\exp\!\big({#1}\big)}} \newcommand{\feq}{{f_\mathrm{eq}}} \newcommand{\FIM}{\mathbf{F}} \newcommand{\FIMm}{F} \newcommand{\floor}[1]{\lfloor #1 \rfloor} \newcommand{\flow}{f_{\mathrm{low}}} \newcommand{\FM}{\mathfrak{F}(\M)} \newcommand{\frobnorm}[2][F]{\left\|{#2}\right\|_\mathrm{#1}} \newcommand{\frobnormbig}[1]{\big\|{#1}\big\|_\mathrm{F}} \newcommand{\frobnormsmall}[1]{\|{#1}\|_\mathrm{F}} \newcommand{\GLr}{{\mathbb{R}^{r\times r}_*}} \newcommand{\Gr}{\mathrm{Gr}} \newcommand{\grad}{\mathrm{grad}} \newcommand{\Hess}{\mathrm{Hess}} \newcommand{\HH}{\mathrm{H}} \newcommand{\Id}{\operatorname{Id}} % need to be distinguishable from identity matrix \newcommand{\II}{I\!I} \newcommand{\inj}{\mathrm{inj}} \newcommand{\inner}[2]{\left\langle{#1},{#2}\right\rangle} \newcommand{\innerbig}[2]{\big\langle{#1},{#2}\big\rangle} \newcommand{\innersmall}[2]{\langle{#1},{#2}\rangle} \newcommand{\ith}{$i$th } \newcommand{\jth}{$j$th } \newcommand{\Klow}{{K_{\mathrm{low}}}} \newcommand{\Kmax}{K_{\mathrm{max}}} \newcommand{\kth}{$k$th } \newcommand{\Kup}{{K_{\mathrm{up}}}} \newcommand{\Klo}{{K_{\mathrm{lo}}}} \newcommand{\lambdamax}{\lambda_\mathrm{max}} \newcommand{\lambdamin}{\lambda_\mathrm{min}} \newcommand{\langevin}{\mathrm{Lang}} \newcommand{\langout}{\mathrm{LangUni}} \newcommand{\length}{\operatorname{length}} \newcommand{\Log}{\mathrm{Log}} \newcommand{\longg}{{\mathrm{long}}} \newcommand{\M}{\mathcal{M}} \newcommand{\mle}{{\mathrm{MLE}}} \newcommand{\mlez}{{\mathrm{MLE0}}} \newcommand{\MSE}{\mathrm{MSE}} \newcommand{\N}{\mathrm{N}} \newcommand{\norm}[1]{\left\|{#1}\right\|} \newcommand{\nulll}{\operatorname{null}} \newcommand{\hull}{\mathrm{hull}} \newcommand{\Od}{{\mathrm{O}(d)}} \newcommand{\On}{{\mathrm{O}(n)}} \newcommand{\One}{\mathds{1}} \newcommand{\Op}{{\mathrm{O}(p)}} \newcommand{\opnormsmall}[1]{\|{#1}\|_\mathrm{op}} \newcommand{\p}{\mathcal{P}} \newcommand{\pa}[1]{\left(#1\right)} \newcommand{\paa}[1]{\left\{#1\right\}} \newcommand{\pac}[1]{\left[#1\right]} \newcommand{\pdd}[1]{\frac{\partial}{\partial #1}} \newcommand{\polar}{\mathrm{polar}} \newcommand{\Precon}{\mathrm{Precon}} \newcommand{\proj}{\mathrm{proj}} \newcommand{\Proj}{\mathrm{Proj}} \newcommand{\ProjH}{\mathrm{Proj}^h} \newcommand{\PSD}{\mathrm{PSD}} \newcommand{\ProjV}{\mathrm{Proj}^v} \newcommand{\qf}{\mathrm{qf}} \newcommand{\rank}{\operatorname{rank}} \newcommand{\Rball}{R_{\mathrm{ball}}} \newcommand{\Rcurv}{\mathcal{R}} \newcommand{\Rd}{{\mathbb{R}^{d}}} \newcommand{\Rdd}{{\mathbb{R}^{d\times d}}} \newcommand{\Rdp}{{\mathbb{R}^{d\times p}}} \newcommand{\reals}{{\mathbb{R}}} \newcommand{\Retr}{\mathrm{R}} \newcommand{\Rk}{{\mathbb{R}^{k}}} \newcommand{\Rm}{{\mathbb{R}^m}} \newcommand{\Rmle}{{\hat\bfR_\mle}} \newcommand{\Rmm}{{\mathbb{R}^{m\times m}}} \newcommand{\Rmn}{{\mathbb{R}^{m\times n}}} \newcommand{\Rmnr}{{\mathbb{R}_r^{m\times n}}} \newcommand{\Rmop}{R_\mathrm{m}} \newcommand{\Rmoptensor}{\mathbf{{R_\mathrm{m}}}} \newcommand{\Rmr}{\mathbb{R}^{m\times r}} \newcommand{\RMSE}{\mathrm{RMSE}} \newcommand{\Rn}{{\mathbb{R}^n}} \newcommand{\Rnk}{\mathbb{R}^{n\times k}} \newcommand{\Rnm}{\mathbb{R}^{n\times m}} \newcommand{\Rnn}{{\mathbb{R}^{n\times n}}} \newcommand{\RNN}{{\mathbb{R}^{N\times N}}} \newcommand{\Rnp}{{\mathbb{R}^{n\times p}}} \newcommand{\Rnr}{\mathbb{R}^{n\times r}} \newcommand{\Rp}{{\mathbb{R}^{p}}} \newcommand{\Rpp}{\mathbb{R}^{p\times p}} \newcommand{\Rrn}{{\mathbb{R}^{r\times n}}} \newcommand{\Rrr}{\mathbb{R}^{r\times r}} \newcommand{\Rtt}{{\mathbb{R}^{3\times 3}}} \newcommand{\sbd}[1]{\sbdop\!\left({#1}\right)} \newcommand{\sbdop}{\operatorname{symblockdiag}} \newcommand{\sbdsmall}[1]{\sbdop({#1})} \newcommand{\Sd}{\mathbb{S}^{d}} \newcommand{\Sdd}{{\mathbb{S}^{d\times d}}} \newcommand{\short}{{\mathrm{short}}} \newcommand{\sigmamax}{\sigma_{\operatorname{max}}} \newcommand{\sigmamin}{\sigma_{\operatorname{min}}} \newcommand{\sign}{\mathrm{sign}} \newcommand{\ske}{\operatorname{skew}} \newcommand{\Skew}{\operatorname{Skew}} \newcommand{\skeww}[1]{\operatorname{skew}\!\left( #1 \right)} \newcommand{\Sm}{\mathbb{S}^{m-1}} \newcommand{\smallfrobnorm}[1]{\|{#1}\|_\mathrm{F}} \newcommand{\Smdmd}{{\mathbb{S}^{md\times md}}} \newcommand{\Smm}{{\mathbb{S}^{m\times m}}} \newcommand{\Sn}{\mathbb{S}^{n-1}} \newcommand{\Snn}{{\mathbb{S}^{n\times n}}} \newcommand{\So}{{\mathbb{S}^{1}}} \newcommand{\SOd}{\operatorname{SO}(d)} \newcommand{\SOdm}{\operatorname{SO}(d)^m} \newcommand{\son}{{\mathfrak{so}(n)}} \newcommand{\SOn}{{\mathrm{SO}(n)}} \newcommand{\sot}{{\mathfrak{so}(3)}} \newcommand{\SOt}{{\mathrm{SO}(3)}} \newcommand{\sotwo}{{\mathfrak{so}(2)}} \newcommand{\SOtwo}{{\mathrm{SO}(2)}} \newcommand{\Sp}{{\mathbb{S}^{2}}} \newcommand{\spann}{\mathrm{span}} \newcommand{\gspan}{\mathrm{gspan}} \newcommand{\Spp}{{\mathbb{S}^{p\times p}}} \newcommand{\sqfrobnorm}[2][F]{\frobnorm[#1]{#2}^2} \newcommand{\sqfrobnormbig}[1]{\frobnormbig{#1}^2} \newcommand{\sqfrobnormsmall}[1]{\frobnormsmall{#1}^2} \newcommand{\sqnorm}[1]{\left\|{#1}\right\|^2} \newcommand{\Srr}{{\mathbb{S}^{r\times r}}} \newcommand{\St}{\mathrm{St}} \newcommand{\Cent}{\mathrm{Centered}} \newcommand{\Holl}{\mathrm{Hollow}} \newcommand{\Stdpm}{\St(d, p)^m} \newcommand{\Stnp}{{\mathrm{St}(n,p)}} \newcommand{\Stwo}{{\mathbb{S}^{2}}} \newcommand{\symm}[1]{\symmop\!\left( #1 \right)} \newcommand{\symmop}{\operatorname{sym}} \newcommand{\symmsmall}[1]{\symmop( #1 )} \newcommand{\Symn}{\mathrm{Sym}(n)} \newcommand{\Symnminp}{\mathrm{Sym}(n-p)} \newcommand{\Symp}{\mathrm{Sym}(p)} \newcommand{\Sym}{\mathrm{Sym}} \newcommand{\T}{\mathrm{T}} \newcommand{\TODO}[1]{{\color{red}{[#1]}}} \newcommand{\trace}{\mathrm{Tr}} \newcommand{\Trace}{\mathrm{Tr}} \newcommand{\Trans}{\mathrm{Transport}} \newcommand{\Transbis}[2]{\mathrm{Transport}_{{#1}}({#2})} \newcommand{\transpose}{^\top\! } \newcommand{\uniform}{\mathrm{Uni}} \newcommand{\var}{\mathrm{var}} \newcommand{\vecc}{\mathrm{vec}} \newcommand{\veccc}[1]{\vecc\left({#1}\right)} \newcommand{\VV}{\mathrm{V}} \newcommand{\XM}{\mathfrak{X}(\M)} \newcommand{\xorigin}{x_{\mathrm{ref}}} \newcommand{\Zeq}{{Z_\mathrm{eq}}} \newcommand{\aref}[1]{\hyperref[#1]{A\ref{#1}}} \newcommand{\frobnorm}[1]{\left\|{#1}\right\|_\mathrm{F}} \newcommand{\sqfrobnorm}[1]{\frobnorm{#1}^2}
Introduction
In our previous blog post, we considered several definitions of p-criticality (through straight lines, curves and neighborhoods), and showed none of these definitions are equivalent. Let’s recall them here:
We concluded that the “right” definition of p-criticality is through neighborhoods, due to the following two properties (not enjoyed by the other definitions).
Propositions 1 and 2 are consequences of the following result.
Proposition 3 is probably known — see these papers of Moussu, Nowel and Szafraniec, and Szafraniec. We present a proof at the end of this post. This proof may be new, and, more importantly, it is self-contained and hopefully easy to parse!
The key tools to prove Propositions 1, 2, 3 are gradient flows and the Łojasiewicz inequality.
Gradient flows
Let f \colon \reals^d \to \reals be C^\infty. A positive gradient flow trajectory started at x_0 \in \reals^d is a solution of the ODE \begin{align}\tag{$+$gradflow} x'(t) = \nabla f(x(t)), \quad \quad t \in \reals, \quad \quad x(0) = x_0. \end{align} Likewise, negative gradient flow is a solution of \begin{align}\tag{$-$gradflow} x'(t) = -\nabla f(x(t)), \quad \quad t \in \reals, \quad \quad x(0) = x_0. \end{align} A gradient flow is always defined on some open interval around t = 0; however, it may not be defined on all of \reals. If \nabla f(x_0) is nonzero then gradient flow never reaches a 1-critical point in finite time (since the flow map \Phi defined below is a diffeomorphism in an appropriate sense). Therefore, the quantity f(x(t)) is always increasing for positive gradient flow with \nabla f(x_0) \neq 0. This is because \frac{d}{dt}[f(x(t))] = \mathrm{D} f(x(t))[x'(t)] = \|\nabla f(x(t))\|^2 > 0 \quad \quad \text{for all $t$}. (And likewise the function value decreases for negative gradient flow.)
We define the positive gradient flow map \Phi by \begin{align}\tag{flowmap} \Phi(x_0, t) = x(t) \end{align} where x(\cdot) is the positive gradient flow starting at x_0. The flow map \Phi is defined on a (open) subset of \reals^d \times \reals (this domain is called the flow’s maximal flow domain). It is a fact that \Phi is differentiable on its domain. Further, for a given t, the map x \mapsto \Phi(x, t) is a diffeomorphism (from the set of points on which it is well defined and onto its image). For more information on vector-field flows more generally, we recommend Chapter 9 “Integral Curves and Flows” of Introduction to Smooth Manifolds by John Lee.
For any F \in \reals, let \tau(F, x_0) denote the first time t \geq 0 at which the positive gradient flow (+gradflow) leaves the sublevel set \{x \in \reals^d : f(x) < F\}, with the convention that \tau(F, x_0) = +\infty if the flow never leaves the sublevel set in finite time. As a shorthand, we also define \tau(x) := \tau(0, x). Note that if \nabla f(x_0) \neq 0 and \tau(F, x_0) is finite, then it is the only time t for which f(x(t)) = F, since f(x(t)) is increasing. For a given F, we can define a map x \mapsto \tau(F, x) from \reals^d to [0, \infty]. We have the following useful fact.
The Łojasiewicz inequality
In the 1960s, Stanisław Łojasiewicz proved the following theorem, which is an extremely useful tool for controlling gradient flows. (Notation: throughout, B(0, \delta) denotes the open ball of radius \delta centered at the origin.)
Inequality (Ł) is known as the Łojasiewicz inequality — its proof is beyond the scope of this blog.
If f satisfies the Łojasiewicz inequality, then its gradient flows cannot stray too far from their starting points.
In Lemma 2, \tau(x(0)) may be either finite or infinite. If it is infinite, then x(t) must converge to a critical point of f (e.g., see the exercise at the end of this section), and x(\tau(x(0))) is that limiting point. Either way, x(\tau(x(0))) lies on the level set \{x : f(x) = 0\}.
The proof of Lemma 2 is classical and originally due to Łojasiewicz. We present a proof based on Theorem 2.2 of this paper by Absil, Mahony and Andrews.
Exercise: Assume f satisfies the Łojasiewicz inequality (Ł) with constants c, \mu in U_L = B(0, \delta_L). Also assume that the gradient flow line x(\cdot) started at x(0) \in U_L stays in U_L for all t \geq 0. Show that x(t) must converge to a critical point of f. [Hint: Use Lemma 2, with a compactness argument.]
Proofs of Propositions 1 and 2: When does p-critical imply local minimum?
We are now ready to prove Proposition 4 below. Propositions 1 and 2 are immediate consequences.
Proposition 1 follows immediately from Proposition 4 and Łojasiewicz’s theorem previously stated.
Proposition 2 follows immediately from Proposition 4, and bounds on the best Łojasiewicz exponent \mu given by D’Acunto and Kurdyka. Specifically, D’Acunto and Kurdyka show that if f \colon \reals^d \to \reals is a degree-k polynomial, then f satisfies the Łojasiewicz inequality with exponenent \mu = 1 - (3 k)^{-d}.
Proof of Proposition 3: every saddle has a gradient flow line converging to it
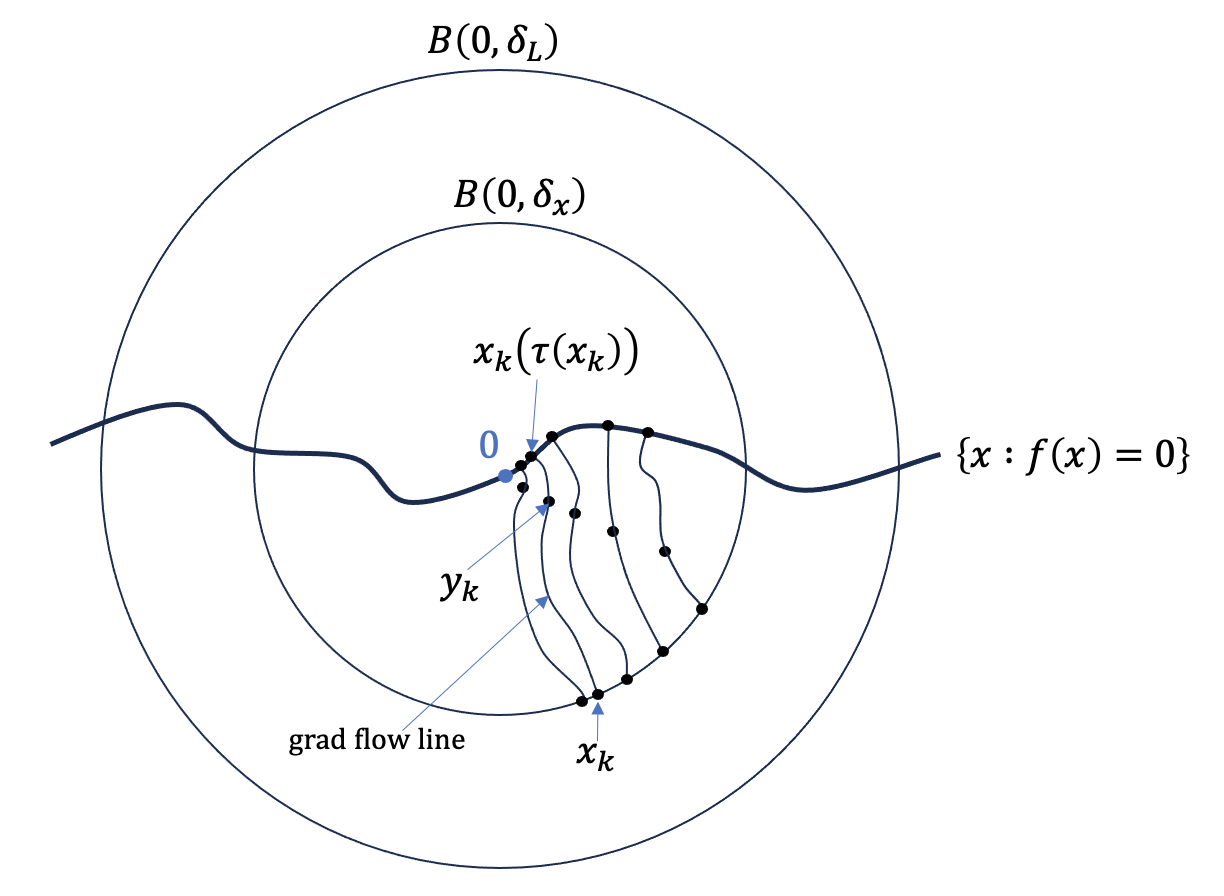
It remains to only prove Proposition 3. The idea is simple. Choose a sequence of points y_0, y_1, \ldots converging to 0 with f(y_k) < 0. For each y_k we look at the positive gradient flow line y_k(\cdot) starting at y_k until it leaves the sublevel set \{x : f(x) < 0\}. By Lemma 2, the endpoints y_k(\tau(y_k)) of the flow lines also converge to 0.
Now run the negative gradient flow starting from y_k until it first hits the boundary of B(0, \delta_x), \delta_x > 0; call the intersection point x_k. Then we know that the positive gradient flow line starting at x_k ends at y_k(\tau(y_k)), which converges to 0 as k \to \infty.
The sequence x_0, x_1, \ldots accumulates to some x_\infty on the boundary of B(0, \delta_x). It stands to reason that the positive gradient flow line started from x_\infty converges to 0. This is indeed true. Let’s look at the details.
How to cite
If you would like to cite this post, you can use:
@misc{criscitiello2024gradientflowslojasiewicz,
author = {Christopher Criscitiello and Quentin Rebjock},
title = {Gradient flows and the {\L}ojasiewicz inequality, with an application to higher-order criticality},
year = {2024},
month = oct,
howpublished = {\url{https://ccriscitiello.github.io/downhillblog/posts/Loja_p_implies_local/}},
note = {Blog post, published October 3, 2024}
}Acknowledgements: We thank Nicolas Boumal for several helpful pointers.